


Next: 7 The ADAPTOR OpenMP
Up: ADAPTOR OpenMP Programmers Guide
Previous: 5 Private and Shared
Contents
So far, the code within a parallel region is executed by all the
threads of the team. Nevertheless, each thread might execute parts
of the computations.
do I = 1, N
A(I) = ...
end do
!$omp parallel private (INODE, NNODE, LB, UB)
NNODE = omp_get_num_threads ()
INODE = omp_get_thread_num()
LB = I * (N / NNODE) + 1
UB = INODE * (N / NNODE)
do LB = UB
A(I) = ..
end do
!$omp end parallel
!$omp do
do I = 1, N
A(I) = ...
end do
New Clauses first met in work-sharing directives are:
- lastprivate (list) - when threads join the variables in
list take on the value they would normally have after the last
loop iteration of sequential execution;
- schedule(static|dynamic|guided|runtime)
- ordered - iterations are performed in the same order as
in sequential execution. The ordered clause binds to the
dynamically enclosing do directive.
- schedule(static,chunk) - round-robin allocation of work to
threads in ``chunks''. Default chunk size is
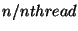 ;
;
- schedule(dynamic,chunk) - dynamic allocation to threads.
Blocks of work of size chunk. Default chunk size is 1;
- schedule(guided,chunk) - this is fully explained in the
documentation.
- schedule(runtime) - allows the system to select the scheduling
at run time using an environment variable, e.g.
OMP_SCHEDULE=''guided,4''.
Next: 7 The ADAPTOR OpenMP
Up: ADAPTOR OpenMP Programmers Guide
Previous: 5 Private and Shared
Contents
Thomas Brandes
2004-03-18