Операция перемножения матриц в задачах линейной алгебры является часто используемой и поэтому ее оптимизированные версии, как правило, включаются в различные математические библиотеки. Так, в частности, существует версия подпрограммы для однопроцессорных систем в библиотеке LAPACK и в ее параллельной версии для систем с распределенной памятью ScaLAPACK. Для нас эта задача представляет интерес, поскольку она достаточно просто распараллеливается и мы можем сравнить эффективность полученного кода с эффективностью библиотечных подпрограмм.
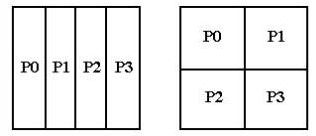
Существует множество вариантов решения этой задачи на многопроцессорных системах. Алгоритм решения существенным образом зависит от того, каким образом производится распределение матриц по процессорам, и какая топология процессоров при этом используется. Как правило, задачи такого типа решаются либо на одномерной сетке процессоров, либо на двумерной. На рис. 4.20 представлено распределение матрицы в памяти 4-х процессоров, образующих одномерную и двумерную сетки.
Рис. 4.20 Пример распределения матрицы на одномерную и двумерную сетки процессоров.
Первый вариант значительно проще в использовании, поскольку позволяет работать с заданным по умолчанию коммуникатором. В случае двумерной
сетки потребуется описать создаваемую топологию и коммуникаторы для каждого направления сетки. Каждая из трех матриц (A,B и С) может быть
распределена одним из 4-х способов:
Отсюда возникает множество вариантов решения этой задачи. Большинство из этих вариантов плохо отражают специфику алгоритма и, соответственно, заведомо будут неэффективны. Тот или иной способ распределения матриц однозначно определяет, какие из трех циклов вычислительного блока должны быть подвержены процедуре редукции.
Ниже предлагается вариант программы решения этой задачи, который в достаточно полной мере учитывает специфику алгоритма. Поскольку для вычисления каждого матричного элемента матрицы С необходимо выполнить скалярное произведение строки матрицы А на столбец матрицы В, то матрица А разложена на одномерную сетку процессоров по строкам, а матрица В - по столбцам. Матрица С разложена по строкам, как матрица А (рис. 4.21).
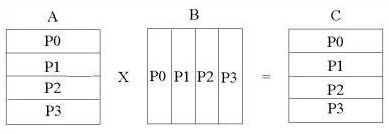
Рис. 4.21 Распределение матриц на одномерную сетку процессоров.
При таком распределении строка, необходимая для вычисления некоторого матричного элемента, гарантированно находится в нужном узле, а столбец хотя и может отсутствовать, но целиком расположен в некотором другом узле. Поэтому алгоритм решения задачи должен предусматривать определение того, в каком процессоре находится нужный столбец матрицы B, и его пересылку в тот узел, который в нем нуждается в данный момент. На самом деле, каждый столбец матрицы B участвует в вычислении всего соответствующего столбца матрицы С, распределенного по всем процессорам, и поэтому его следует рассылать во все процессоры. Следует отметить, что разбиение матриц, представленное на Рис. 4.21 более подходит для программы на языке С, поскольку в этом языке элементы матрицы располагаются по строкам. В программе на Фортране, представленной ниже, разбиение матрицы С сделано по столбцам, и такое разбиение значительно увеличивает скорость работы фортрановской программы за счет более эффективного использования кэш-памяти.
Программа на pmatmult.f
PROGRAM PMATMULT INCLUDE 'mpif.h' INTEGER NM,NPS REAL(KIND=8), DIMENSION(:,:), allocatable :: A,B,C REAL(KIND=8), DIMENSION(:), allocatable :: ROW INTEGER(KIND=4), DIMENSION(:), allocatable :: NB,NS REAL*8 TIME,OP,MF,DDOT,S С Инициализация MPI CALL MPI_INIT(IERR) CALL MPI_COMM_RANK(MPI_COMM_WORLD,IAM,IERR) CALL MPI_COMM_SIZE(MPI_COMM_WORLD,NPROCS,IERR) C Считывание размерности матриц IF(IAM.EQ.0)THEN OPEN( 10, FILE='abc.dat', STATUS='OLD' ) READ (10,*) NM END IF С Рассылка считанного параметра по процессорам call MPI_BCAST(NM,1,MPI_INTEGER,0,MPI_COMM_WORLD,ierr) С Выделение необходимой памяти под массивы на каждом процессоре. С Предполагается, что массив А разбит по строкам, а массивы В С и С по столбцам. NPS = NM/NPROCS + 1 allocate ( NB(0:NPROCS-1) ) allocate ( NS(0:NPROCS-1) ) allocate ( A(NPS,NM) ) allocate ( B(NM,NPS) ) allocate ( C(NM,NPS) ) allocate ( ROW(NM) ) С Определение параметров декомпозиции матрицы С NB - размер блока матрицы в каждом процессоре С NS - номер строки или столбца, начиная с которого С хранится матрица в данном процессоре OP = (2.D0*NM-1)*NM*NM IF(IAM.EQ.0) WRITE(*,*) 'NM = ',NM,' NPROCS = ',NPROCS NB1 = NM/NPROCS NB2 = MOD(NM,NPROCS) DO I = 0,NPROCS-1 NB(I) = NB1 END DO DO I = 0,NB2-1 NB(I)= NB(I)+1 END DO NS(0)=0 DO I = 1,NPROCS-1 NS(I)= NS(I-1) + NB(I-1) END DO С Начальная инициализация массивов C Массив A(I,J) = I, массив B(I,J) = 1/J DO J = 1,NM DO I = 1,NB(IAM) A(I,J) = DBLE(I+NS(IAM)) END DO END DO DO I = 1,NM DO J = 1,NB(IAM) B(I,J) =1./DBLE(J+NS(IAM)) END DO END DO TIME = MPI_WTIME() C Цикл по строка разбит на две части: по блокам разбиения и С по элементам внутри блоков. Это избавляет от необходимости С определения, в каком процессоре находится данная строка. I = 0 DO I1 = 0,NPROCS-1 DO I2 = 1,NB(I1) I = I + 1 IF(IAM.EQ.I1) THEN DO N = 1,NM ROW(N) = A(I2,N) END DO END IF CALL MPI_BCAST(ROW,NM,MPI_DOUBLE_PRECISION,I1, *MPI_COMM_WORLD,IERR) С Цикл по столбцам выполняется только для блока, находящегося С в данном процессоре DO J = 1,NB(IAM) S = 0.0 DO K = 1,NM S = S + ROW(K)*B(K,J) END DO C(I,J) = S END DO END DO END DO TIME = MPI_WTIME() -TIME MF = OP/(TIME*1000000) С Печать контрольных матричных элементов IF(IAM.EQ.0) WRITE(*,*) IAM,C(1,1),C(NM,1) IF(IAM.EQ.NPROCS-1) *WRITE(*,*) IAM,C(1,NB(NPROCS-1)),C(NM,NB(NPROCS-1)) IF(IAM.EQ.0) WRITE(*,*) ' TIME CALCULATION: ', TIME, *' MFLOPS: ',MF CALL MPI_FINALIZE(IERR) END
Суть распараллеливания в данной программе заключается в том, что каждый процессор вычисляет свой блок матрицы C, который составляет приблизительно 1/NPROCS часть полной матрицы. Нетрудно заметить, что пересылки данных не потребовались бы, если бы матрица А не распределялась по процессорам, а целиком хранилась в каждом процессоре (для программы на языке Фортран). В некоторых случаях такая асимметрия в распределении матриц бывает очень выгодна.