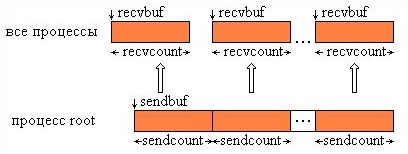
Семейство функций распределения блоков данных по всем процессам группы состоит из двух подпрограмм: MPI_Scatter и MPI_Scaterv.
Функция MPI_Scatter разбивает сообщение из буфера посылки процесса root на равные части размером sendcount и посылает i-ю часть в буфер приема процесса с номером i (в том числе и самому себе). Процесс root использует оба буфера (посылки и приема), поэтому в вызываемой им подпрограмме все параметры являются существенными. Остальные процессы группы с коммуникатором comm являются только получателями, поэтому для них параметры, специфицирующие буфер посылки, не существенны.
Тип посылаемых элементов sendtype должен совпадать с типом recvtype получаемых элементов, а число посылаемых элементов sendcount должно равняться числу принимаемых recvcount. Следует обратить внимание, что значение sendcount в вызове из процесса root - это число посылаемых каждому процессу элементов, а не общее их количество. Операция Scatter является обратной по отношению к Gather. На рис. 4.5 представлена графическая интерпретация операции Scatter.
Рис. 4.5. Графическая интерпретация операции Scatter.
Функция MPI_Scaterv является векторным вариантом функции MPI_Scatter, позволяющим посылать каждому процессу различное количество элементов. Начало расположения элементов блока, посылаемого i-му процессу, задается в массиве смещений displs, а число посылаемых элементов - в массиве sendcounts. Эта функция является обратной по отношению к функции MPI_Gatherv.
На рис. 4.6 представлена графическая интерпретация операции Scatterv.
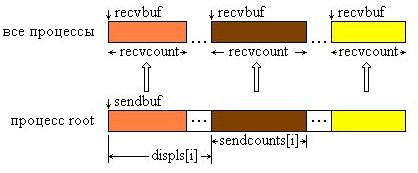
Рис. 4.6. Графическая интерпретация операции Scatterv.
Приведем пример программы, использующей функцию Scatter
Программа scatter.c
#include <stdio.h>
#include "mpi.h"
#define SIZE 4
int main(argc,argv)
int argc;
char *argv[]; {
int numtasks, rank, sendcount, recvcount, source;
float sendbuf[SIZE][SIZE] = {
{1.0, 2.0, 3.0, 4.0},
{5.0, 6.0, 7.0, 8.0},
{9.0, 10.0, 11.0, 12.0},
{13.0, 14.0, 15.0, 16.0} };
float recvbuf[SIZE];
MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &numtasks);
if (numtasks == SIZE) {
source = 1;
sendcount = SIZE;
recvcount = SIZE;
MPI_Scatter(sendbuf,sendcount,MPI_FLOAT,recvbuf,recvcount,
MPI_FLOAT,source,MPI_COMM_WORLD);
printf("rank= %d Results: %f %f %f %f\n",rank,recvbuf[0],
recvbuf[1],recvbuf[2],recvbuf[3]);
}
else
printf("Must specify %d processors. Terminating.\n",SIZE);
MPI_Finalize();
}
Программа scatter.f
program scatter include 'mpif.h' integer SIZE parameter(SIZE=4) integer numtasks, rank, sendcount, recvcount, source,ierr real*4 sendbuf(SIZE,SIZE), recvbuf(SIZE) data sendbuf /1.0, 2.0, 3.0, 4.0, & 5.0, 6.0, 7.0, 8.0, & 9.0, 10.0, 11.0, 12.0, & 13.0, 14.0, 15.0, 16.0 / call MPI_INIT(ierr) call MPI_COMM_RANK(MPI_COMM_WORLD, rank, ierr) call MPI_COMM_SIZE(MPI_COMM_WORLD, numtasks, ierr) if (numtasks .eq. SIZE) then source = 1 sendcount = SIZE recvcount = SIZE call MPI_SCATTER(sendbuf, sendcount, MPI_REAL, recvbuf, & recvcount, MPI_REAL, source, MPI_COMM_WORLD, ierr) print *, 'rank= ',rank,' Results: ',recvbuf else print *, 'Must specify',SIZE,' processors. Terminating.' endif call MPI_FINALIZE(ierr) end