Семейство функций сбора блоков данных от всех процессов группы состоит из четырех подпрограмм: MPI_Gather, MPI_Allgather, MPI_Gatherv, MPI_Allgatherv. Каждая из указанных подпрограмм расширяет функциональные возможности предыдущих.
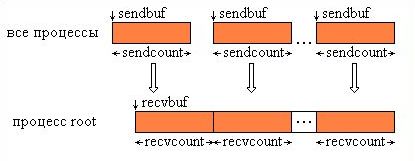
Функция MPI_Gather производит сборку блоков данных, посылаемых всеми процессами группы, в один массив процесса с номером root. Длина блоков предполагается одинаковой. Объединение происходит в порядке увеличения номеров процессов-отправителей. То есть данные, посланные процессом i из своего буфера sendbuf, помещаются в i-ю порцию буфера recvbuf процесса root. Длина массива, в который собираются данные, должна быть достаточной для их размещения.
Тип посылаемых элементов sendtype должен совпадать с типом recvtype получаемых элементов, а число sendcount должно равняться числу recvcount. То есть, recvcount в вызове из процесса root - это число собираемых от каждого процесса элементов, а не общее количество собранных элементов. Графическая интерпретация операции Gather представлена на Рис. 4.2.
Рис. 4.2. Графическая интерпретация операции Gather.
Функция MPI_Allgather выполняется так же, как MPI_Gather, но получателями являются все процессы группы. Данные, посланные процессом i из своего буфера sendbuf, помещаются в i-ю порцию буфера recvbuf каждого процесса. После завершения операции содержимое буферов приема recvbuf у всех процессов одинаково.
Графическая интерпретация операции Allgater представлена на рис 4.3. На этой схеме ось Y образуют процессы группы, а ось X блоки данных.
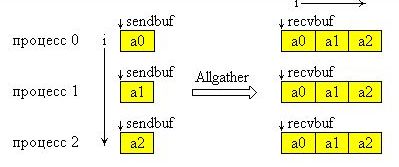
Рис 4.3. Графическая интерпретация операции Аllgather.
Функция MPI_Gatherv позволяет собирать блоки с разным числом элементов от каждого процесса, так как количество элементов, принимаемых от каждого процесса, задается индивидуально с помощью массива recvcounts. Эта функция обеспечивает также большую гибкость при размещении данных в процессе-получателе, благодаря введению в качестве параметра массива смещений displs.
Сообщения помещаются в буфер приема процесса root в соответствии с номерами посылающих процессов, а именно, данные, посланные процессом i, размещаются в адресном пространстве процесса root, начиная с адреса rbuf + displs[i]. Графическая интерпретация операции Gatherv представлена на рис. 4.4.
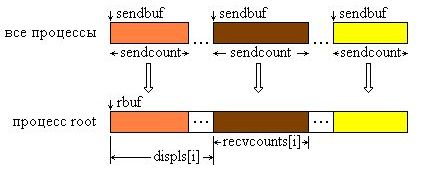
Рис. 4.4. Графическая интерпретация операции Gatherv.
Функция MPI_Allgatherv является аналогом функции MPI_Gatherv, но сборка выполняется всеми процессами группы. Поэтому в списке параметров отсутствует параметр root.
Приведем пример программы на использование функций сбора данных.
Программа gather.c
#include <stdio.h>
#include "mpi.h"
int main(int argc,char *argv[])
{
int iam,nproc;
int nl,len,i,j,k;
int *iar,*iar_all;
MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD,&iam);
MPI_Comm_size(MPI_COMM_WORLD,&nproc);
if (iam == 0) nl=10;
MPI_Bcast(&nl,1,MPI_INT,0,MPI_COMM_WORLD);
len = nl * nproc;
iar = malloc(nl * sizeof(int));
iar_all = malloc(len * sizeof(int));
for( i = 0; i < nl; i++ ){
iar[i] = iam * nl + i+1;
}
MPI_Gather(iar,nl,MPI_INT,iar_all,nl,MPI_INT,0,MPI_COMM_WORLD);
if ( iam == 0 ){
k =0;
for( i = 0; i < nproc; i++){
for( j = 0; j < nl; j++){
printf("%3d ",iar_all[k]);
k++;
}
printf("\n");
}
}
MPI_Finalize();
return 0;
}
Программа gather.f
program gather include 'mpif.h' integer i,j,IAM,NPROC,ierr,len,nl integer, dimension(:), allocatable :: iar, iar_all CALL MPI_INIT(ierr) CALL MPI_COMM_SIZE(MPI_COMM_WORLD,NPROC,ierr) CALL MPI_COMM_RANK(MPI_COMM_WORLD,IAM,ierr) if(IAM.EQ.0) then nl = 10 end if CALL MPI_Bcast(nl,1,MPI_INTEGER,0,MPI_COMM_WORLD,ierr) len = nl*NPROC allocate ( iar(1:nl)) allocate ( iar_all(1:len)) do i = 1,nl iar(i) = IAM*nl + i end do CALL MPI_Gather(iar, nl, MPI_INTEGER, iar_all, nl, * MPI_INTEGER, 0, MPI_COMM_WORLD, ierr) if (IAM.EQ.0 ) write (*,10) iar_all 10 format(2x, 10I4) CALL MPI_FINALIZE(ierr) END