Вперед: 1.4.4. Заключение к главе 1
Назад: 1.4.2.4. Язык параллельного программирования HPF
К содержанию: Оглавление
1.4.3. Эффективность параллельных программ
Использование многопроцессорных систем позволяет надеяться, что скорость выполнения вычислений увеличится в n раз, если используется n
процессоров вместо одного. Однако на практике ускорение оказывается значительно меньше ожидаемого. Уменьшение роста производительности при
параллельных вычислениях обусловлено двумя факторами: первый связан со свойствами алгоритма программы - эти свойства исследовал в 1967 г.
разработчик суперкомпьютеров Джин Амдал, а второй - с техническими свойствами вычислительной системы. Исследование Амдала завершилось
формулировкой закона Амдала, который наложил жесткое ограничение на ускорение выполнения параллельной программы при увеличении числа процессоров.
Суть проблемы состоит в том, что каждая параллельная программа содержит какую-то часть не параллельного кода. На системах с общей памятью это
та часть кода, которая выполняется только головной нитью, а на системах с распределенной памятью это часть кода, которая выполняется всеми
процессами. Предположим, что отношение времени выполнения непараллельной части программы ко всему времени выполнения равно
f (0 < f < 1). Если время выполнения на одном процессоре равно 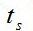 , то время выполнения параллельной части -
, то время выполнения параллельной части -
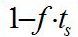 , а время выполнения последовательной части -
, а время выполнения последовательной части - 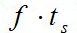 . В идеальном
случае, при использовании n процессоров, время выполнения параллельной части составит
. В идеальном
случае, при использовании n процессоров, время выполнения параллельной части составит 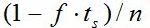 , а время
выполнения последовательной части останется .
, а время
выполнения последовательной части останется .
Таким образом, ускорение выполнения программы на n процессорах составит
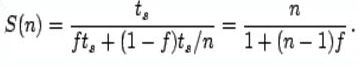 |
(1.2) |
Формула 1.2 и составляет суть закона Амдала [20]. При n, стремящемся к бесконечности, ускорение составит 1/f.
Из этого закона следует, что если доля непараллельного кода в программе составляет 5%, то невозможно получить более чем 20-кратное ускорение
программы, сколько бы процессоров не использовалось. На рис. 1.5 представлен график зависимости теоретически достижимого ускорения для такой
программы в зависимости от числа процессоров. Из этого графика видно, что кривая достаточно быстро достигает асимптотических значений, и
дальнейшее увеличение числа процессоров становится неоправданным. Идеальный случай линейного роста ускорения работы программы при увеличении
числа процессоров возможен только когда f = 0. На реальных программах ускорение будет еще меньше, поскольку формула не учитывает издержки на
пересылки данных. Более того, если учесть технические издержки, то окажется, что кривая на Рис. 1.5 будет иметь максимум, который указывает на
то, что при некотором значении количества процессоров ускорение начнет уменьшаться. Таким образом, закон Амдала очень наглядно демонстрирует,
насколько сложно создавать высокоэффективные параллельные программы.
При разбиении большой задачи на более мелкие подзадачи, которые должны выполняться параллельно на различных процессорах, часто возникает
ситуация, когда нужно ждать завершения выполнения некоторого этапа всеми процессорами. В этом случае полное время выполнения будет определяться
самой медленной подзадачей. Поэтому, при разработке параллельной программы чрезвычайно важно максимально равномерно распределять вычислительную
работу между процессорами. Это называется балансировкой загрузки, и ее достижение представляет собой нетривиальную задачу.
В системах с общей памятью, в которых обмен информацией между процессорами происходит посредством переменных, хранящихся в общей памяти,
синхронизация процессов особенно важна. Если несколько процессов одновременно пытаются модифицировать одну и ту же переменную, то необходим
специальный механизм синхронизации выполнения процессов, для обеспечения детерминированности выполнения программы.
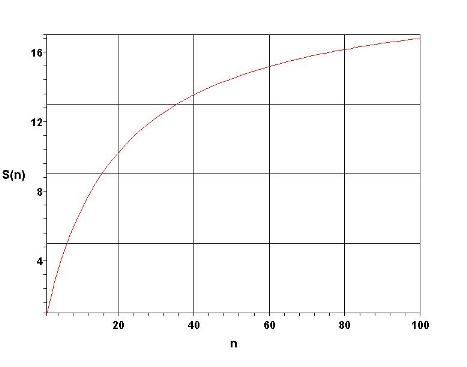
Рис. 1.5. Ускорение работы программы с f=0.05 на различном числе процессоров.
Как отмечалось ранее, все современные микропроцессоры снабжаются скоростной кэш-памятью, которая работает на той же частоте, что и процессор,
и позволяет значительно увеличить скорость обработки данных, находящихся в ней.
Для этого данные из основной памяти предварительно переписываются в кэш-память. Этот механизм прекрасно и без проблем работает на
однопроцессорных системах, однако требует специального обслуживания на многопроцессорных системах. Если одна и та же переменная находится в
кэш-памяти нескольких процессоров и один из процессоров модифицирует ее, то ее значение должно быть модифицировано в кэш-памяти всех процессоров.
Этот механизм называется сохранением когерентности кэш-памяти. Программисту не требуется заботиться о когерентности кэшей - это реализовано
на аппаратном уровне. Однако поддержка когерентности приводит к замедлению работы программы, и это следует учитывать при разработке
параллельных программ.
Эффективность параллельных программ на системах с распределенной памятью существенным образом зависит от коммуникационной среды.
Достаточно полно коммуникационная среда характеризуется двумя параметрами: полосой пропускания (bandwidth), которая определяет количество байт,
передаваемых в единицу времени, и латентностью (latency), которая определяет время, затрачиваемое на подготовку к передаче сообщения. Для сети
Gigabit Ethernet полоса пропускания в MPI программах составляет около 70 Мб/сек, а латентность около 40 мксек. Для большого числа задач, в
которых обмены данными происходят редко и невелики по объему, эти параметры являются вполне удовлетворительными, однако, в случаях, когда в
программе передается много мелких сообщений, такие параметры становятся неприемлемыми, и масштабируемость программы оказывается чрезвычайно
низкой. В последнее время все более популярным становится коммуникационное оборудование Infiniband, которое, при сравнительно невысокой
стоимости обеспечивает полосу пропускания 3-5 Гб/сек, при латентности чуть более 1 мксек. В любом случае, коммуникационные операции
выполняются значительно медленнее, чем обращения к локальной памяти, поэтому наиболее эффективными будут те параллельные программы, в
которых обмены сведены к минимуму.
Вперед: 1.4.4. Заключение к главе 1
Назад: 1.4.2.4. Язык параллельного программирования HPF
К содержанию: Оглавление