





Preface
This is the reference manual for the Sun Performance Library, which is a library of subroutines and functions to perform useful operations in computational linear algebra. This introductory section provides background information as well as information about storage conventions that you will need to know in order to use the Sun Performance Library. This reference manual contains a chapter for each of the seven standard libraries (FFTPACK and VFFTPACK are combined in one chapter) implemented in the Sun Performance Library; each chapter describes the subprograms for that library. To help in locating subprogram descriptions, the table of contents lists all the subprograms descriptively by function and appendix A lists all the subprograms alphabetically by name.
Sun Performance Library
The Sun Performance Library is based on the standard libraries LAPACK, LINPACK, BLAS1, BLAS2, BLAS3, FFTPACK, and VFFTPACK with extensions to support a C/C++ language interface. The Sun Performance Library versions of these subprograms perform the same operation and the FORTRAN-callable subroutines have the same interface as the standard versions, but the Sun Performance Library versions are generally faster and sometimes more accurate. Sun Performance Library subprograms achieve their speed by taking advantage of specific features of the hardware and software with which they are run. Some subprograms achieve additional speedup by using more than one CPU on MP systems.
Using the Sun Performance Library on Solaris 1
The Solaris 1 version was compiled with the Sun SC3.0.1 FORTRAN and SC3.0 CC compilers using -cg89 and -dalign compilation options. When using the C/C++ interfaces with a C compiler, remember to compile so that float arguments that are passed by value are not promoted to double during the call. When the prototype for a C/C++ function shows an argument as float x, the function expects to receive a 32-bit floating point value. When using C++, prototypes must be prefaced with the extern "C" qualifier. Your program must be compiled and linked with -dalign and linked with -lsunperf.
Using the Sun Performance Library on Solaris 2
The Solaris 2 versions were compiled with the Sun SC4.2 FORTRAN and C compilers using -dalign and -xarch set to one of [v7 | v8 | v8plusa]. For each -xarch option used to compile the libraries, there is a library compiled with -xparallel and a library compiled without -xparallel. When linking your program, use -dalign, -xlic_lib=sunperf, and the same -xarch option that you used when compiling. If you cannot use -dalign in your program then you must supply a trap 6 handler as described in /opt/SUNWspro/SC4.2/READMEs/performance_library. Your system administrator may have moved this file from its default location. If you compile with a value of -xarch that is not one of [v7 | v8 | v8plusa] then the compiler driver will select the closest match.
Sun Performance Library is a licensed library and so it is linked into an application with the -xlic_lib switch rather than the -l switch that is used to link in other libraries. The -xlic_lib switch is equivalent to the -l switch except that -xlic_lib links with a licensed library and directs the compiler driver to include a licensing step to allow the executable file to run. The -xlic_lib and -l switches are otherwise identical including the fact that the -xlic_lib switch must be specified on the command line after any of the files that use Sun Performance Library. An example of the use of -xlic_lib is shown below:
dakota% f77 -dalign my_file.f -xlic_lib=sunperf
|
There are two models of parallelism available, one that is optimized for a dedicated machine and another for a shared machine. The shared multiprocessor model of parallelism has the following features:
-
The parallelism model assumes a machine shared among many tasks.
-
Parallelization is implemented with threads library synchronization primitives.
The dedicated multiprocessor model of parallelism has the following features:
-
The parallelism model assumes a machine dedicated to one task.
-
Parallelization is implemented with spin locks.
On a dedicated system, the dedicated model can be somewhat faster than the shared model due to lower synchronization overhead. On a system running many different tasks, the shared model provides better cooperation in the use of available resources. If you use one of [-xparallel | -xexplicitpar | -xautopar] on the compile and link lines then you will get the dedicated MP model. If you use -mt on the link line without one of the compiler parallelization options then you will get the shared model. If you do not specify any of the compiler parallelization options or -mt on the link line then your code will not use multiple processors.
If you compile with one of the compiler parallelization options then use the same parallelization option on the linking command. If you would like to use multiple processors then add -mt to the link line and then specify the number of processors at run-time with the PARALLEL environment variable. For example, to use 24 processors, you could enter the commands shown below:
dakota% f77 -fast -mt my_app.f -xlic_lib=sunperf
dakota% setenv PARALLEL 24
dakota% ./a.out
|
If you use the shared model with one of the compiler parallelization options then the behavior is unpredictable.
Using the Sun Performance Library on Solaris 2 for x86
The Solaris 2 versions were compiled with the Sun SC4.2 FORTRAN and C compilers. Sun Performance Library is a licensed library and so it is linked into an application with the -xlic_lib switch rather than the -l switch that is used to link in other libraries. The -xlic_lib switch is equivalent to the -l switch except that -xlic_lib links with a licensed library and directs the compiler driver to include a licensing step to allow the executable file to run. The -xlic_lib and -l switches are otherwise identical including the fact that the -xlic_lib switch must be specified on the command line after any of the files that use Sun Performance Library. An example of the use of -xlic_lib is shown below:
dakota% f77 my_file.f -xlic_lib=sunperf
|
If you would like to use multiple processors then add -mt to the link line and then specify the number of processors at run-time with the PARALLEL environment variable. For example, to use 12 processors, you could enter the commands shown below:
dakota% f77 -fast -mt my_app.f -xlic_lib=sunperf
dakota% setenv PARALLEL 12
dakota% ./a.out
|
Using the Native C/C++ Interface to Sun Performance Library
The C/C++ interfaces to subprograms in LAPACK, BLAS, LINPACK, FFTPACK, and VFFTPACK in Sun Performance Library are completely different from the FORTRAN interface to the standard libraries in Netlib. In addition, the C/C++ interfaces to LAPACK in Sun Performance Library differ from interfaces to the Netlib CLAPACK. There are three major differences between the C/C++ interface to Sun Performance Library and the FORTRAN interfaces to the standard libraries in Netlib. First, scalar arguments that are used only as inputs are passed by value in Sun Performance Library. Complex and double complex arguments are not considered scalars because they are not implemented as a scalar type by C. Second, arguments relating to workspace are not used in Sun Performance Library. Third, array indices are based at zero in conformance with C conventions rather than being based at one to conform to FORTRAN conventions. As an example of these changes, compare the standard LAPACK FORTRAN interface with the C/C++ interface in Sun Performance Library shown below with the DGBCON subprogram.
CALL DGBCON (NORM, N, NSUB, NSUPER, DA, LDA, IPIVOT, DANORM,
DRCOND, DWORK, IWORK2, INFO)
|
void dgbcon (char norm, long int n, long int, long int nsuper,
double *da, long int lda, long int *ipivot, double
danorm, double *drcond, long int *info)
|
Note that the names of the arguments are the same and that arguments with the same name have the same base type. Scalar arguments that are used only as input values, such as NORM and N, are passed by value in the C/C++ version. Arrays and scalars that will be used to return values are passed by reference.
Compatibility
The Fortran functions and subroutines are used by calling them from within a program, usually, but not necessarily, a FORTRAN 77 or Fortran 90 program. For instance, the calling program can be C or C++. However, the calling program must use the FORTRAN 77 calling sequence.
-
Do not prototype the subroutines with Fortran 90's INTERFACE statement. The use of INTERFACE implies that the subroutines will use the Fortran 90 calling sequence, and this is not the case. Call the subroutines in the same way that you would call any FORTRAN 77 subroutine.
-
Arrays are stored columnwise.
-
All arguments are passed by reference.
-
The number of arguments to a routine is fixed.
-
Types of arguments must match even after C or C++ does type conversion. For example, care must be exercised when passing a single precision real value because a C or C++ compiler may automatically promote the argument to double precision.
-
Indices are base at one in keeping with standard Fortran practice.
The C interfaces are used by calling them from within a program, usually, but not necessarily, a C or C++ program. For instance, the calling program can be a Pascal or Ada program. However, the calling sequence must follow these rules:
-
Arrays are stored columnwise. This differs from standard C and C++ conventions.
-
Indices are based at zero in keeping with standard C and C++ practice. For example, the FORTRAN interface to IDAMAX, which C programs access as
"idamax_", would return a 1 to indicate the first element in a vector. The C interface to idamax, which C programs access as "idamax", would return a 0 to indicate the first element of a vector. This convention is observed in function return values, permutation vectors, and anywhere else that vector or array indices are used.
Special Storage Schemes
The Sun Performance Library processes matrices that are in one of four forms: general, triangular, symmetric (or Hermitian), or tridiagonal. The general form is the most common and most operations performed by the Sun Performance Library can be done on general arrays. In many cases, there also are subprograms that will work with the other forms of the arrays. For example, DGEMM will form the product of two general matrices and DTRMM will form the product of a triangular and a general matrix.
Most of these matrices can be stored in ways that save both storage space and computation time. The two types of storage that Sun Performance Library uses are banded storage and packed storage. Some of the subprograms that work with arrays stored normally have corresponding subprograms that take advantage of these special storage forms. For example, DGBMV will form the product of a general matrix in banded storage and a vector, and DTPMV will form the product of a triangular matrix in packed storage and a vector.
The storage forms and the four types of matrices are discussed and shown below.
Banded Storage
A banded matrix is stored so the jth column of the matrix corresponds to the jth column of the FORTRAN array. See the discussion of array forms for examples.
The following code is an example of taking a banded general matrix in a general array and copying it into banded storage mode.
C Copy the matrix A from the array AG to the array AB. The
C matrix is stored in general storage mode in AG and it will
C be stored in banded storage mode in AB. The code to copy
C from general to banded storage mode is taken from the
C comment block in the original DGBFA by Cleve Moler.
C
NSUB = 1
NSUPER = 2
NDIAG = NSUB + 1 + NSUPER
DO 10, ICOL = 1, N
I1 = MAX0 (1, ICOL - NSUPER)
I2 = MIN0 (N, ICOL + NSUB)
DO 10, IROW = I1, I2
IROWB = IROW - ICOL + NDIAG
AB(IROWB,ICOL) = AG(IROW,ICOL)
10 CONTINUE
20 CONTINUE
|
Note that this method of storing banded matrices is compatible with the storage method used by BLAS, LINPACK, and LAPACK, but is inconsistent with the method used by EISPACK.
Packed Storage
A packed vector is an alternate representation for triangular, symmetric, or Hermitian matrices. An array is packed into a vector by storing sequentially column by column into the vector. Space for the diagonal elements is always reserved even if the values of the diagonal elements are known, for example in a unit diagonal matrix. See the discussion of array forms for examples.
An upper triangular matrix or a symmetric (or Hermitian) matrix whose upper triangle is stored in general storage in the array A can be transferred to packed storage in the array AP as shown below. This code comes from the comment block of the LAPACK subroutine DTPTRI:
JC = 1
DO 20, J = 1, N
DO 10, I = 1, J
AP(JC+I-1) = A(I,J)
10 CONTINUE
JC = JC + J
20 CONTINUE
|
Similarly, a lower triangular matrix or a symmetric (or Hermitian) matrix whose lower triangle is stored in general storage in the array A can be transferred to packed storage in the array AP as shown below:
JC = 1
DO 20, J = 1, N
DO 10, I = J, N
AP(JC+I-1) = A(I,J)
10 CONTINUE
JC = JC + N - J + 1
20 CONTINUE
|
General Matrices
A general matrix is stored so that there is a one-to-one correspondence between the elements of the matrix and the elements of the array. Element Aij of a matrix A is stored in element A(I,J) of the corresponding array A. The general form is the most common form. A general matrix, because it is dense, has no special storage scheme. In a general banded matrix, however, the diagonal of the matrix is stored in the row below the upper diagonals. For example, the banded general matrix below can be represented with banded storage as shown below. Elements shown with the symbol 5 are never accessed by subprograms that process banded arrays.
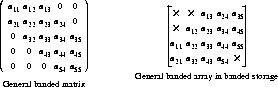
Triangular Matrices
A triangular matrix is stored so that there is a one-to-one correspondence between the non-zero elements of the matrix and the elements of the array, but the elements of the array corresponding to the zero elements of the matrix are never accessed by subprograms that process triangular arrays.
A triangular matrix can be stored using packed storage:

A triangular banded matrix can be stored using banded storage as shown below. Elements shown with the symbol 5 are never accessed by subprograms that process banded arrays.

Symmetric (or Hermitian) Matrices
A symmetric (or Hermitian) matrix is similar to a triangular matrix in that the data in either the upper or lower triangle corresponds to the elements of the array. The contents of the other elements in the array are assumed and those array elements are never accessed by subprograms that process symmetric or Hermitian arrays. The imaginary elements on the main diagonal of a Hermitian matrix are assumed to be zero on entry to a subroutine.
A symmetric (or Hermitian) matrix can be stored using packed storage:

A symmetric (or Hermitian) banded matrix can be stored using banded storage as shown below. Elements shown with the symbol 5 are never accessed by subprograms that process banded arrays.
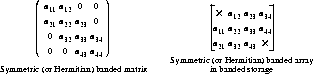
Tridiagonal Matrices
A tridiagonal matrix has elements only on the main diagonal, the first superdiagonal, and the first subdiagonal. It is stored using three 1-dimensional arrays:
