This chapter describes the basic usage of FFTW, i.e., how to compute the Fourier transform of a single array. This chapter tells the truth, but not the whole truth. Specifically, FFTW implements additional routines and flags, providing extra functionality, that are not documented here. See Section FFTW Reference, for more complete information. (Note that you need to compile and install FFTW before you can use it in a program. See Section Installation and Customization, for the details of the installation.)
Here, we assume a default installation of FFTW. In some installations
(particulary from binary packages), the FFTW header files and libraries
are prefixed with `d' or `s' to indicate
versions in double or single precision, respectively. The usage of FFTW
in that case is the same, except that #include directives and
link commands must use the appropriate prefix. See Section Installing FFTW in both single and double precision, for more information.
This tutorial chapter is structured as follows. Section Complex One-dimensional Transforms Tutorial describes the basic usage of the one-dimensional transform of complex data. Section Complex Multi-dimensional Transforms Tutorial describes the basic usage of the multi-dimensional transform of complex data. Section Real One-dimensional Transforms Tutorial describes the one-dimensional transform of real data and its inverse. Finally, Section Real Multi-dimensional Transforms Tutorial describes the multi-dimensional transform of real data and its inverse. We recommend that you read these sections in the order that they are presented. We then discuss two topics in detail. In Section Multi-dimensional Array Format, we discuss the various alternatives for storing multi-dimensional arrays in memory. Section Words of Wisdom shows how you can save FFTW's plans for future use.
The basic usage of FFTW is simple. A typical call to FFTW looks like:
#include <fftw.h>
...
{
fftw_complex in[N], out[N];
fftw_plan p;
...
p = fftw_create_plan(N, FFTW_FORWARD, FFTW_ESTIMATE);
...
fftw_one(p, in, out);
...
fftw_destroy_plan(p);
}
The first thing we do is to create a plan, which is an object that contains all the data that FFTW needs to compute the FFT, using the following function:
fftw_plan fftw_create_plan(int n, fftw_direction dir, int flags);
The first argument, n, is the size of the transform you are
trying to compute. The size n can be any positive integer, but
sizes that are products of small factors are transformed most
efficiently. The second argument, dir, can be either
FFTW_FORWARD or FFTW_BACKWARD, and indicates the direction
of the transform you
are interested in. Alternatively, you can use the sign of the exponent
in the transform, -1 or +1, which corresponds to
FFTW_FORWARD or FFTW_BACKWARD respectively. The
flags argument is either FFTW_MEASURE or
FFTW_ESTIMATE. FFTW_MEASURE means that FFTW actually runs
and measures the execution time of several FFTs in order to find the
best way to compute the transform of size n. This may take some
time, depending on your installation and on the precision of the timer
in your machine. FFTW_ESTIMATE, on the contrary, does not run
any computation, and just builds a
reasonable plan, which may be sub-optimal. In other words, if your
program performs many transforms of the same size and initialization
time is not important, use FFTW_MEASURE; otherwise use the
estimate. (A compromise between these two extremes exists. See Section Words of Wisdom.)
Once the plan has been created, you can use it as many times as you like
for transforms on arrays of the same size. When you are done with the
plan, you deallocate it by calling fftw_destroy_plan(plan).
The transform itself is computed by passing the plan along with the
input and output arrays to fftw_one:
void fftw_one(fftw_plan plan, fftw_complex *in, fftw_complex *out);
Note that the transform is out of place: in and out must
point to distinct arrays. It operates on data of type
fftw_complex, a data structure with real (in[i].re) and
imaginary (in[i].im) floating-point components. The in
and out arrays should have the length specified when the plan was
created. An alternative function, fftw, allows you to
efficiently perform multiple and/or strided transforms (see Section FFTW Reference).
The DFT results are stored in-order in the array out, with the
zero-frequency (DC) component in out[0].
The array in is not modified. Users should note that FFTW
computes an unnormalized DFT, the sign of whose exponent is given by the
dir parameter of fftw_create_plan. Thus, computing a
forward followed by a backward transform (or vice versa) results in the
original array scaled by n. See Section What FFTW Really Computes,
for the definition of DFT.
A program using FFTW should be linked with -lfftw -lm on Unix
systems, or with the FFTW and standard math libraries in general.
FFTW can also compute transforms of any number of dimensions
(rank). The syntax is similar to that for the one-dimensional
transforms, with `fftw_' replaced by `fftwnd_' (which stands
for "fftw in N dimensions").
As before, we #include <fftw.h> and create a plan for the
transforms, this time of type fftwnd_plan:
fftwnd_plan fftwnd_create_plan(int rank, const int *n,
fftw_direction dir, int flags);
rank is the dimensionality of the array, and can be any
non-negative integer. The next argument, n, is a pointer to an
integer array of length rank containing the (positive) sizes of
each dimension of the array. (Note that the array will be stored in
row-major order. See Section Multi-dimensional Array Format, for information
on row-major order.) The last two parameters are the same as in
fftw_create_plan. We now, however, have an additional possible
flag, FFTW_IN_PLACE, since fftwnd supports true in-place
transforms. Multiple flags are combined using a bitwise or
(`|'). (An in-place transform is one in which the output
data overwrite the input data. It thus requires half as much memory
as--and is often faster than--its opposite, an out-of-place
transform.)
For two- and three-dimensional transforms, FFTWND provides alternative
routines that accept the sizes of each dimension directly, rather than
indirectly through a rank and an array of sizes. These are otherwise
identical to fftwnd_create_plan, and are sometimes more
convenient:
fftwnd_plan fftw2d_create_plan(int nx, int ny,
fftw_direction dir, int flags);
fftwnd_plan fftw3d_create_plan(int nx, int ny, int nz,
fftw_direction dir, int flags);
Once the plan has been created, you can use it any number of times for
transforms of the same size. When you do not need a plan anymore, you
can deallocate the plan by calling fftwnd_destroy_plan(plan).
Given a plan, you can compute the transform of an array of data by calling:
void fftwnd_one(fftwnd_plan plan, fftw_complex *in, fftw_complex *out);
Here, in and out point to multi-dimensional arrays in
row-major order, of the size specified when the plan was created. In
the case of an in-place transform, the out parameter is ignored
and the output data are stored in the in array. The results are
stored in-order, unnormalized, with the zero-frequency component in
out[0].
A forward followed by a backward transform (or vice-versa) yields the
original data multiplied by the size of the array (i.e. the product of
the dimensions). See Section What FFTWND Really Computes, for a discussion
of what FFTWND computes.
For example, code to perform an in-place FFT of a three-dimensional array might look like:
#include <fftw.h>
...
{
fftw_complex in[L][M][N];
fftwnd_plan p;
...
p = fftw3d_create_plan(L, M, N, FFTW_FORWARD,
FFTW_MEASURE | FFTW_IN_PLACE);
...
fftwnd_one(p, &in[0][0][0], NULL);
...
fftwnd_destroy_plan(p);
}
Note that in is a statically-declared array, which is
automatically in row-major order, but we must take the address of the
first element in order to fit the type expected by fftwnd_one.
(See Section Multi-dimensional Array Format.)
If the input data are purely real, you can save roughly a factor of two in both time and storage by using the rfftw transforms, which are FFTs specialized for real data. The output of a such a transform is a halfcomplex array, which consists of only half of the complex DFT amplitudes (since the negative-frequency amplitudes for real data are the complex conjugate of the positive-frequency amplitudes).
In exchange for these speed and space advantages, the user sacrifices some of the simplicity of FFTW's complex transforms. First of all, to allow maximum performance, the output format of the one-dimensional real transforms is different from that used by the multi-dimensional transforms. Second, the inverse transform (halfcomplex to real) has the side-effect of destroying its input array. Neither of these inconveniences should pose a serious problem for users, but it is important to be aware of them. (Both the inconvenient output format and the side-effect of the inverse transform can be ameliorated for one-dimensional transforms, at the expense of some performance, by using instead the multi-dimensional transform routines with a rank of one.)
The computation of the plan is similar to that for the complex
transforms. First, you #include <rfftw.h>. Then, you create a
plan (of type rfftw_plan) by calling:
rfftw_plan rfftw_create_plan(int n, fftw_direction dir, int flags);
n is the length of the real array in the transform (even
for halfcomplex-to-real transforms), and can be any positive integer
(although sizes with small factors are transformed more efficiently).
dir is either FFTW_REAL_TO_COMPLEX or
FFTW_COMPLEX_TO_REAL.
The flags parameter is the same as in fftw_create_plan.
Once created, a plan can be used for any number of transforms, and is
deallocated when you are done with it by calling
rfftw_destroy_plan(plan).
Given a plan, a real-to-complex or complex-to-real transform is computed by calling:
void rfftw_one(rfftw_plan plan, fftw_real *in, fftw_real *out);
(Note that fftw_real is an alias for the floating-point type for
which FFTW was compiled.) Depending upon the direction of the plan,
either the input or the output array is halfcomplex, and is stored in
the following format:
r0, r1, r2, ..., rn/2, i(n+1)/2-1, ..., i2, i1
Here,
rk
is the real part of the kth output, and
ik
is the imaginary part. (We follow here the C convention that integer
division is rounded down, e.g. 7 / 2 = 3.) For a halfcomplex
array hc[], the kth component has its real part in
hc[k] and its imaginary part in hc[n-k], with the
exception of k == 0 or n/2 (the latter only
if n is even)---in these two cases, the imaginary part is zero due to
symmetries of the real-complex transform, and is not stored. Thus, the
transform of n real values is a halfcomplex array of length
n, and vice versa. (1) This is actually only half of the DFT
spectrum of the data. Although the other half can be obtained by
complex conjugation, it is not required by many applications such as
convolution and filtering.
Like the complex transforms, the RFFTW transforms are unnormalized, so a
forward followed by a backward transform (or vice-versa) yields the
original data scaled by the length of the array, n.
Let us reiterate here our warning that an FFTW_COMPLEX_TO_REAL
transform has the side-effect of destroying its (halfcomplex) input.
The FFTW_REAL_TO_COMPLEX transform, however, leaves its (real)
input untouched, just as you would hope.
As an example, here is an outline of how you might use RFFTW to compute the power spectrum of a real array (i.e. the squares of the absolute values of the DFT amplitudes):
#include <rfftw.h>
...
{
fftw_real in[N], out[N], power_spectrum[N/2+1];
rfftw_plan p;
int k;
...
p = rfftw_create_plan(N, FFTW_REAL_TO_COMPLEX, FFTW_ESTIMATE);
...
rfftw_one(p, in, out);
power_spectrum[0] = out[0]*out[0]; /* DC component */
for (k = 1; k < (N+1)/2; ++k) /* (k < N/2 rounded up) */
power_spectrum[k] = out[k]*out[k] + out[N-k]*out[N-k];
if (N % 2 == 0) /* N is even */
power_spectrum[N/2] = out[N/2]*out[N/2]; /* Nyquist freq. */
...
rfftw_destroy_plan(p);
}
Programs using RFFTW should link with -lrfftw -lfftw -lm on Unix,
or with the FFTW, RFFTW, and math libraries in general.
FFTW includes multi-dimensional transforms for real data of any rank. As with the one-dimensional real transforms, they save roughly a factor of two in time and storage over complex transforms of the same size. Also as in one dimension, these gains come at the expense of some increase in complexity--the output format is different from the one-dimensional RFFTW (and is more similar to that of the complex FFTW) and the inverse (complex to real) transforms have the side-effect of overwriting their input data.
To use the real multi-dimensional transforms, you first #include
<rfftw.h> and then create a plan for the size and direction of
transform that you are interested in:
rfftwnd_plan rfftwnd_create_plan(int rank, const int *n,
fftw_direction dir, int flags);
The first two parameters describe the size of the real data (not the
halfcomplex data, which will have different dimensions). The last two
parameters are the same as those for rfftw_create_plan. Just as
for fftwnd, there are two alternate versions of this routine,
rfftw2d_create_plan and rfftw3d_create_plan, that are
sometimes more convenient for two- and three-dimensional transforms.
Also as in fftwnd, rfftwnd supports true in-place transforms, specified
by including FFTW_IN_PLACE in the flags.
Once created, a plan can be used for any number of transforms, and is
deallocated by calling rfftwnd_destroy_plan(plan).
Given a plan, the transform is computed by calling one of the following two routines:
void rfftwnd_one_real_to_complex(rfftwnd_plan plan,
fftw_real *in, fftw_complex *out);
void rfftwnd_one_complex_to_real(rfftwnd_plan plan,
fftw_complex *in, fftw_real *out);
As is clear from their names and parameter types, the former function is
for FFTW_REAL_TO_COMPLEX transforms and the latter is for
FFTW_COMPLEX_TO_REAL transforms. (We could have used only a
single routine, since the direction of the transform is encoded in the
plan, but we wanted to correctly express the datatypes of the
parameters.) The latter routine, as we discuss elsewhere, has the
side-effect of overwriting its input (except when the rank of the array
is one). In both cases, the out parameter is ignored for
in-place transforms.
The format of the complex arrays deserves careful attention.
Suppose that the real data has dimensions
n1 x n2 x ... x nd
(in row-major order). Then, after a real-to-complex transform, the
output is an
n1 x n2 x ... x (nd/2+1)
array of fftw_complex values in row-major order, corresponding to
slightly over half of the output of the corresponding complex transform.
(Note that the division is rounded down.) The ordering of the data is
otherwise exactly the same as in the complex case. (In principle, the
output could be exactly half the size of the complex transform output,
but in more than one dimension this requires too complicated a format to
be practical.) Note that, unlike the one-dimensional RFFTW, the real
and imaginary parts of the DFT amplitudes are here stored together in
the natural way.
Since the complex data is slightly larger than the real data, some
complications arise for in-place transforms. In this case, the final
dimension of the real data must be padded with extra values to
accommodate the size of the complex data--two extra if the last
dimension is even and one if it is odd.
That is, the last dimension of the real data must physically contain
2 * (nd/2+1)
fftw_real values (exactly enough to hold the complex data).
This physical array size does not, however, change the logical
array size--only
nd
values are actually stored in the last dimension, and
nd
is the last dimension passed to rfftwnd_create_plan.
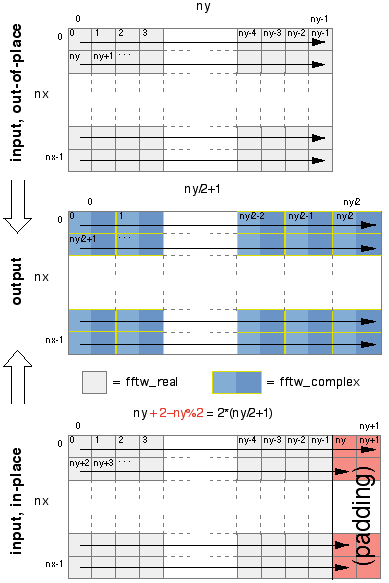
For example, consider the transform of a two-dimensional real array of
size nx by ny. The output of the rfftwnd transform
is a two-dimensional complex array of size nx by ny/2+1,
where the y dimension has been cut nearly in half because of
redundancies in the output. Because fftw_complex is twice the
size of fftw_real, the output array is slightly bigger than the
input array. Thus, if we want to compute the transform in place, we
must pad the input array so that it is of size nx by
2*(ny/2+1). If ny is even, then there are two padding
elements at the end of each row (which need not be initialized, as they
are only used for output).
The following illustration depicts the input and output arrays just
described, for both the out-of-place and in-place transforms (with the
arrows indicating consecutive memory locations):
The RFFTWND transforms are unnormalized, so a forward followed by a backward transform will result in the original data scaled by the number of real data elements--that is, the product of the (logical) dimensions of the real data.
Below, we illustrate the use of RFFTWND by showing how you might use it
to compute the (cyclic) convolution of two-dimensional real arrays
a and b (using the identity that a convolution corresponds
to a pointwise product of the Fourier transforms). For variety,
in-place transforms are used for the forward FFTs and an out-of-place
transform is used for the inverse transform.
#include <rfftw.h>
...
{
fftw_real a[M][2*(N/2+1)], b[M][2*(N/2+1)], c[M][N];
fftw_complex *A, *B, C[M][N/2+1];
rfftwnd_plan p, pinv;
fftw_real scale = 1.0 / (M * N);
int i, j;
...
p = rfftw2d_create_plan(M, N, FFTW_REAL_TO_COMPLEX,
FFTW_ESTIMATE | FFTW_IN_PLACE);
pinv = rfftw2d_create_plan(M, N, FFTW_COMPLEX_TO_REAL,
FFTW_ESTIMATE);
/* aliases for accessing complex transform outputs: */
A = (fftw_complex*) &a[0][0];
B = (fftw_complex*) &b[0][0];
...
for (i = 0; i < M; ++i)
for (j = 0; j < N; ++j) {
a[i][j] = ... ;
b[i][j] = ... ;
}
...
rfftwnd_one_real_to_complex(p, &a[0][0], NULL);
rfftwnd_one_real_to_complex(p, &b[0][0], NULL);
for (i = 0; i < M; ++i)
for (j = 0; j < N/2+1; ++j) {
int ij = i*(N/2+1) + j;
C[i][j].re = (A[ij].re * B[ij].re
- A[ij].im * B[ij].im) * scale;
C[i][j].im = (A[ij].re * B[ij].im
+ A[ij].im * B[ij].re) * scale;
}
/* inverse transform to get c, the convolution of a and b;
this has the side effect of overwriting C */
rfftwnd_one_complex_to_real(pinv, &C[0][0], &c[0][0]);
...
rfftwnd_destroy_plan(p);
rfftwnd_destroy_plan(pinv);
}
We access the complex outputs of the in-place transforms by casting
each real array to a fftw_complex pointer. Because this is a
"flat" pointer, we have to compute the row-major index ij
explicitly in the convolution product loop.
In order to normalize the convolution, we must multiply by a scale
factor--we can do so either before or after the inverse transform, and
choose the former because it obviates the necessity of an additional
loop.
Notice the limits of the loops and the dimensions of the various arrays.
As with the one-dimensional RFFTW, an out-of-place
FFTW_COMPLEX_TO_REAL transform has the side-effect of overwriting
its input array. (The real-to-complex transform, on the other hand,
leaves its input array untouched.) If you use RFFTWND for a rank-one
transform, however, this side-effect does not occur. Because of this
fact (and the simpler output format), users may find the RFFTWND
interface more convenient than RFFTW for one-dimensional transforms.
However, RFFTWND in one dimension is slightly slower than RFFTW because
RFFTWND uses an extra buffer array internally.
This section describes the format in which multi-dimensional arrays are
stored. We felt that a detailed discussion of this topic was necessary,
since it is often a source of confusion among users and several
different formats are common. Although the comments below refer to
fftwnd, they are also applicable to the rfftwnd routines.
The multi-dimensional arrays passed to fftwnd are expected to be
stored as a single contiguous block in row-major order (sometimes
called "C order"). Basically, this means that as you step through
adjacent memory locations, the first dimension's index varies most
slowly and the last dimension's index varies most quickly.
To be more explicit, let us consider an array of rank d whose dimensions are n1 x n2 x n3 x ... x nd. Now, we specify a location in the array by a sequence of (zero-based) indices, one for each dimension: (i1, i2, i3,..., id). If the array is stored in row-major order, then this element is located at the position id + nd * (id-1 + nd-1 * (... + n2 * i1)).
Note that each element of the array must be of type fftw_complex;
i.e. a (real, imaginary) pair of (double-precision) numbers. Note also
that, in fftwnd, the expression above is multiplied by the stride
to get the actual array index--this is useful in situations where each
element of the multi-dimensional array is actually a data structure or
another array, and you just want to transform a single field. In most
cases, however, you use a stride of 1.
Readers from the Fortran world are used to arrays stored in column-major order (sometimes called "Fortran order"). This is essentially the exact opposite of row-major order in that, here, the first dimension's index varies most quickly.
If you have an array stored in column-major order and wish to transform
it using fftwnd, it is quite easy to do. When creating the plan,
simply pass the dimensions of the array to fftwnd_create_plan in
reverse order. For example, if your array is a rank three
N x M x L matrix in column-major order, you should pass the
dimensions of the array as if it were an L x M x N matrix (which
it is, from the perspective of fftwnd). This is done for you
automatically by the FFTW Fortran wrapper routines (see Section Calling FFTW from Fortran).
Multi-dimensional arrays declared statically (that is, at compile time,
not necessarily with the static keyword) in C are already
in row-major order. You don't have to do anything special to transform
them. (See Section Complex Multi-dimensional Transforms Tutorial, for an
example of this sort of code.)
Often, especially for large arrays, it is desirable to allocate the arrays dynamically, at runtime. This isn't too hard to do, although it is not as straightforward for multi-dimensional arrays as it is for one-dimensional arrays.
Creating the array is simple: using a dynamic-allocation routine like
malloc, allocate an array big enough to store N fftw_complex
values, where N is the product of the sizes of the array dimensions
(i.e. the total number of complex values in the array). For example,
here is code to allocate a 5x12x27 rank 3 array:
fftw_complex *an_array; an_array = (fftw_complex *) malloc(5 * 12 * 27 * sizeof(fftw_complex));
Accessing the array elements, however, is more tricky--you can't simply
use multiple applications of the `[]' operator like you could for
static arrays. Instead, you have to explicitly compute the offset into
the array using the formula given earlier for row-major arrays. For
example, to reference the (i,j,k)-th element of the array
allocated above, you would use the expression an_array[k + 27 * (j
+ 12 * i)].
This pain can be alleviated somewhat by defining appropriate macros, or, in C++, creating a class and overloading the `()' operator.
A different method for allocating multi-dimensional arrays in C is often
suggested that is incompatible with fftwnd: using it will
cause FFTW to die a painful death. We discuss the technique here,
however, because it is so commonly known and used. This method is to
create arrays of pointers of arrays of pointers of ...etcetera. For
example, the analogue in this method to the example above is:
int i,j;
fftw_complex ***a_bad_array; /* another way to make a 5x12x27 array */
a_bad_array = (fftw_complex ***) malloc(5 * sizeof(fftw_complex **));
for (i = 0; i < 5; ++i) {
a_bad_array[i] =
(fftw_complex **) malloc(12 * sizeof(fftw_complex *));
for (j = 0; j < 12; ++j)
a_bad_array[i][j] =
(fftw_complex *) malloc(27 * sizeof(fftw_complex));
}
As you can see, this sort of array is inconvenient to allocate (and
deallocate). On the other hand, it has the advantage that the
(i,j,k)-th element can be referenced simply by
a_bad_array[i][j][k].
If you like this technique and want to maximize convenience in accessing
the array, but still want to pass the array to FFTW, you can use a
hybrid method. Allocate the array as one contiguous block, but also
declare an array of arrays of pointers that point to appropriate places
in the block. That sort of trick is beyond the scope of this
documentation; for more information on multi-dimensional arrays in C,
see the comp.lang.c
FAQ.
FFTW implements a method for saving plans to disk and restoring them.
In fact, what FFTW does is more general than just saving and loading
plans. The mechanism is called wisdom. Here, we describe
this feature at a high level. See Section FFTW Reference, for a less casual
(but more complete) discussion of how to use wisdom in FFTW.
Plans created with the FFTW_MEASURE option produce near-optimal
FFT performance, but it can take a long time to compute a plan because
FFTW must actually measure the runtime of many possible plans and select
the best one. This is designed for the situations where so many
transforms of the same size must be computed that the start-up time is
irrelevant. For short initialization times but slightly slower
transforms, we have provided FFTW_ESTIMATE. The wisdom
mechanism is a way to get the best of both worlds. There are, however,
certain caveats that the user must be aware of in using wisdom.
For this reason, wisdom is an optional feature which is not
enabled by default.
At its simplest, wisdom provides a way of saving plans to disk so
that they can be reused in other program runs. You create a plan with
the flags FFTW_MEASURE and FFTW_USE_WISDOM, and then save
the wisdom using fftw_export_wisdom:
plan = fftw_create_plan(..., ... | FFTW_MEASURE | FFTW_USE_WISDOM);
fftw_export_wisdom(...);
The next time you run the program, you can restore the wisdom
with fftw_import_wisdom, and then recreate the plan using the
same flags as before. This time, however, the same optimal plan will be
created very quickly without measurements. (FFTW still needs some time
to compute trigonometric tables, however.) The basic outline is:
fftw_import_wisdom(...);
plan = fftw_create_plan(..., ... | FFTW_USE_WISDOM);
Wisdom is more than mere rote memorization, however. FFTW's
wisdom encompasses all of the knowledge and measurements that
were used to create the plan for a given size. Therefore, existing
wisdom is also applied to the creation of other plans of
different sizes.
Whenever a plan is created with the FFTW_MEASURE and
FFTW_USE_WISDOM flags, wisdom is generated. Thereafter,
plans for any transform with a similar factorization will be computed
more quickly, so long as they use the FFTW_USE_WISDOM flag. In
fact, for transforms with the same factors and of equal or lesser size,
no measurements at all need to be made and an optimal plan can be
created with negligible delay!
For example, suppose that you create a plan for
N = 216.
Then, for any equal or smaller power of two, FFTW can create a
plan (with the same direction and flags) quickly, using the
precomputed wisdom. Even for larger powers of two, or sizes that
are a power of two times some other prime factors, plans will be
computed more quickly than they would otherwise (although some
measurements still have to be made).
The wisdom is cumulative, and is stored in a global, private data
structure managed internally by FFTW. The storage space required is
minimal, proportional to the logarithm of the sizes the wisdom was
generated from. The wisdom can be forgotten (and its associated
memory freed) by a call to fftw_forget_wisdom(); otherwise, it is
remembered until the program terminates. It can also be exported to a
file, a string, or any other medium using fftw_export_wisdom and
restored during a subsequent execution of the program (or a different
program) using fftw_import_wisdom (these functions are described
below).
Because wisdom is incorporated into FFTW at a very low level, the
same wisdom can be used for one-dimensional transforms,
multi-dimensional transforms, and even the parallel extensions to FFTW.
Just include FFTW_USE_WISDOM in the flags for whatever plans you
create (i.e., always plan wisely).
Plans created with the FFTW_ESTIMATE plan can use wisdom,
but cannot generate it; only FFTW_MEASURE plans actually produce
wisdom. Also, plans can only use wisdom generated from
plans created with the same direction and flags. For example, a size
42 FFTW_BACKWARD transform will not use wisdom
produced by a size 42 FFTW_FORWARD transform. The only
exception to this rule is that FFTW_ESTIMATE plans can use
wisdom from FFTW_MEASURE plans.
For in much wisdom is much grief, and he that increaseth knowledge increaseth sorrow. [Ecclesiastes 1:18]
There are pitfalls to using wisdom, in that it can negate FFTW's
ability to adapt to changing hardware and other conditions. For example,
it would be perfectly possible to export wisdom from a program
running on one processor and import it into a program running on another
processor. Doing so, however, would mean that the second program would
use plans optimized for the first processor, instead of the one it is
running on.
It should be safe to reuse wisdom as long as the hardware and
program binaries remain unchanged. (Actually, the optimal plan may
change even between runs of the same binary on identical hardware, due
to differences in the virtual memory environment, etcetera. Users
seriously interested in performance should worry about this problem,
too.) It is likely that, if the same wisdom is used for two
different program binaries, even running on the same machine, the plans
may be sub-optimal because of differing code alignments. It is
therefore wise to recreate wisdom every time an application is
recompiled. The more the underlying hardware and software changes
between the creation of wisdom and its use, the greater grows the
risk of sub-optimal plans.
void fftw_export_wisdom_to_file(FILE *output_file); fftw_status fftw_import_wisdom_from_file(FILE *input_file);
fftw_export_wisdom_to_file writes the wisdom to
output_file, which must be a file open for
writing. fftw_import_wisdom_from_file reads the wisdom
from input_file, which must be a file open for reading, and
returns FFTW_SUCCESS if successful and FFTW_FAILURE
otherwise. In both cases, the file is left open and must be closed by
the caller. It is perfectly fine if other data lie before or after the
wisdom in the file, as long as the file is positioned at the
beginning of the wisdom data before import.
char *fftw_export_wisdom_to_string(void); fftw_status fftw_import_wisdom_from_string(const char *input_string)
fftw_export_wisdom_to_string allocates a string, exports the
wisdom to it in NULL-terminated format, and returns a
pointer to the string. If there is an error in allocating or writing
the data, it returns NULL. The caller is responsible for
deallocating the string (with fftw_free) when she is done with
it. fftw_import_wisdom_from_string imports the wisdom from
input_string, returning FFTW_SUCCESS if successful and
FFTW_FAILURE otherwise.
Exporting wisdom does not affect the store of wisdom. Imported
wisdom supplements the current store rather than replacing it
(except when there is conflicting wisdom, in which case the older
wisdom is discarded). The format of the exported wisdom is
"nerd-readable" LISP-like ASCII text; we will not document it here
except to note that it is insensitive to white space (interested users
can contact us for more details).
See Section FFTW Reference, for more information, and for a description of
how you can implement wisdom import/export for other media
besides files and strings.
The following is a brief example in which the wisdom is read from
a file, a plan is created (possibly generating more wisdom), and
then the wisdom is exported to a string and printed to
stdout.
{
fftw_plan plan;
char *wisdom_string;
FILE *input_file;
/* open file to read wisdom from */
input_file = fopen("sample.wisdom", "r");
if (FFTW_FAILURE == fftw_import_wisdom_from_file(input_file))
printf("Error reading wisdom!\n");
fclose(input_file); /* be sure to close the file! */
/* create a plan for N=64, possibly creating and/or using wisdom */
plan = fftw_create_plan(64,FFTW_FORWARD,
FFTW_MEASURE | FFTW_USE_WISDOM);
/* ... do some computations with the plan ... */
/* always destroy plans when you are done */
fftw_destroy_plan(plan);
/* write the wisdom to a string */
wisdom_string = fftw_export_wisdom_to_string();
if (wisdom_string != NULL) {
printf("Accumulated wisdom: %s\n",wisdom_string);
/* Just for fun, destroy and restore the wisdom */
fftw_forget_wisdom(); /* all gone! */
fftw_import_wisdom_from_string(wisdom_string);
/* wisdom is back! */
fftw_free(wisdom_string); /* deallocate it since we're done */
}
}
Go to the first, previous, next, last section, table of contents.